arXiv 2026PriorVLA: Prior-Preserving Adaptation for Vision-Language-Action ModelsXinyu Guo, Bin Xie, Wei Chai, Xianchi Deng, Tiancai Wang, Zhengxing Wu, Xingyu ChenPrior knowledge maintenance and efficient downstream fine-tuning in VLA models.PDFProject
arXiv 2026World-Ego Modeling for Long-Horizon Evolution in Hybrid Embodied TasksZuyao Lin, Jianhui Zhang, Peidong Jia, Xiaoguang Zhao, Shanghang Zhang, Xingyu ChenA video-based world-ego modeling framework for long-horizon evolution in hybrid embodied tasks.PDFProject
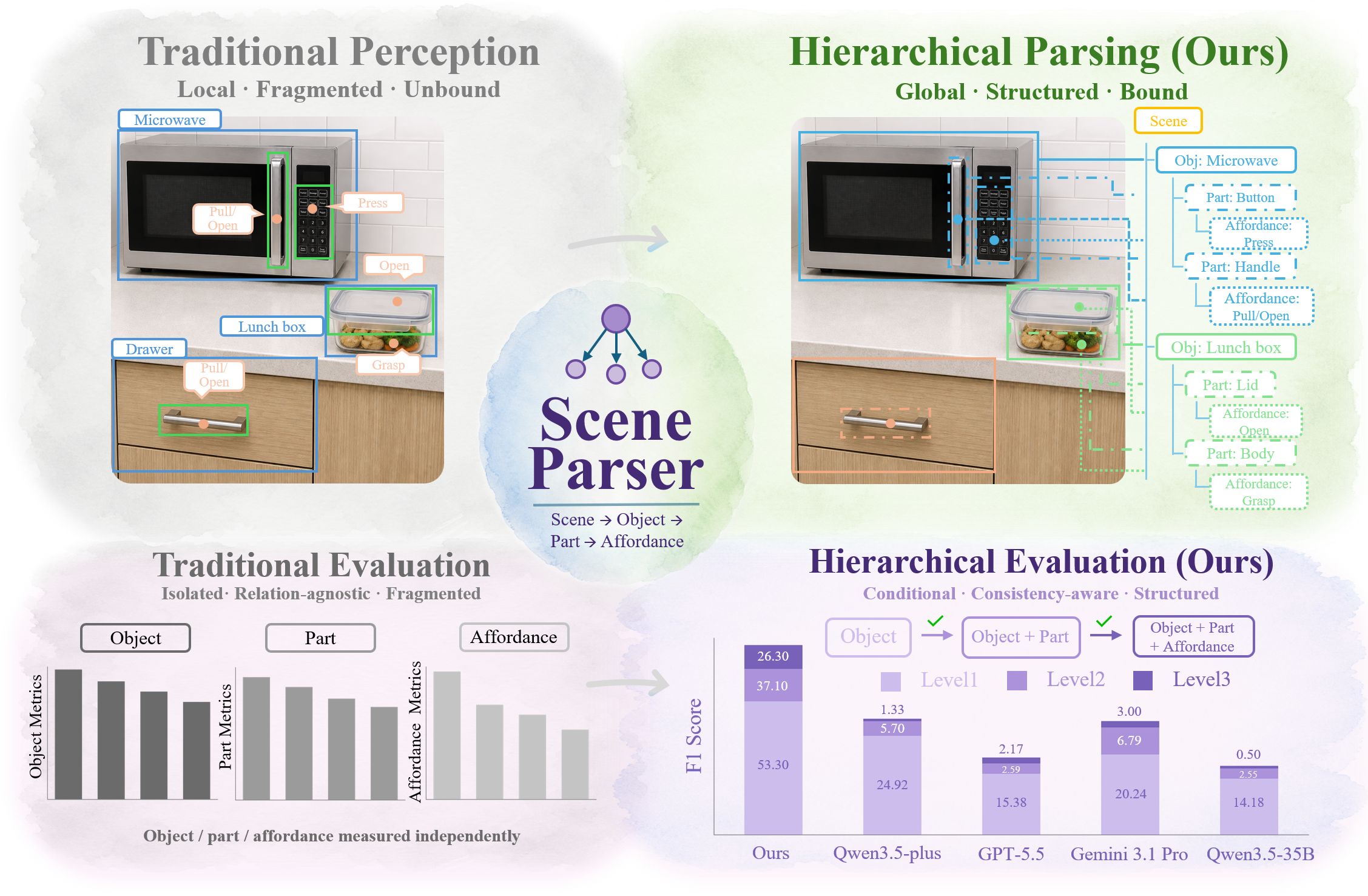
arXiv 2026SceneParser: Hierarchical Scene Parsing for Visual Semantics UnderstandingPengxin Xu, Xincheng Lin, Luping Xiao, Qing Jiang, Meishan Zhang, Hao Fei, Shanghang Zhang, Xingyu ChenA hierarchical scene parsing framework for comprehensive visual semantic understanding.PDFCode
ACM MM 2026GeoHand: Unlocking Prior Geometry Knowledge for Monocular 3D Hand ReconstructionWeiquan Lin, Yaoqing Hu, Liangchen Dai, Xu Tang, Xingyu ChenGeoHand leverages prior geometry knowledge for monocular 3D hand reconstruction.PDF
arXiv 2026VLingNav: Embodied Navigation with Adaptive Reasoning and Visual-Assisted Linguistic MemoryShaoan Wang*, Yuanfei Luo*, Xingyu Chen ✉, Aocheng Luo, Dongyue Li, Chang Liu, Sheng Chen, Yangang Zhang, Junzhi Yu ✉VLingNav combines adaptive reasoning with visual-assisted linguistic memory for persistent cross-modal semantic memory in long-horizon navigation.PDFProject
CVPR 2026Detect Anything via Next Point PredictionQing Jiang, Junan Huo, Xingyu Chen, Yuda Xiong, Zhaoyang Zeng, Yihao Chen, Tianhe Ren, Junzhi Yu, Lei ZhangA unified framework for point-based visual cognition based on LLMs.PDFProject
ICLR 2026Rex-Thinker: Grounded Object Refering via Chain-of-Thought ReasoningQing Jiang*, Xingyu Chen*, Zhaoyang Zeng, Junzhi Yu, Lei ZhangObject referring is reformulated as a Chain-of-Thought reasoning task that verifies candidate object regions step by step.PDFProject